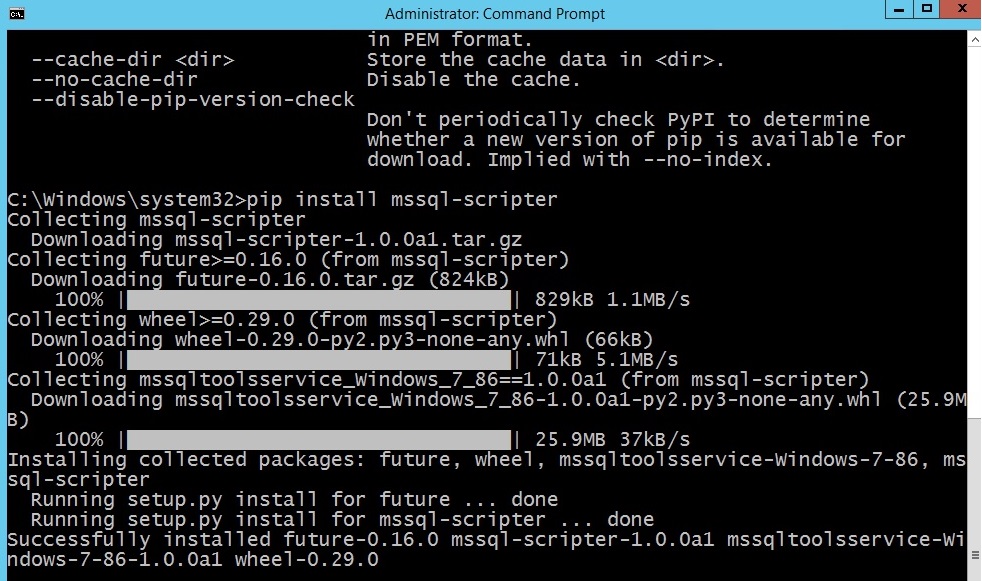
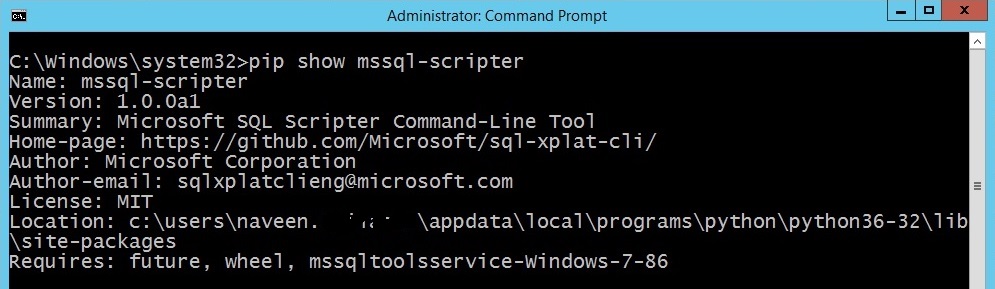
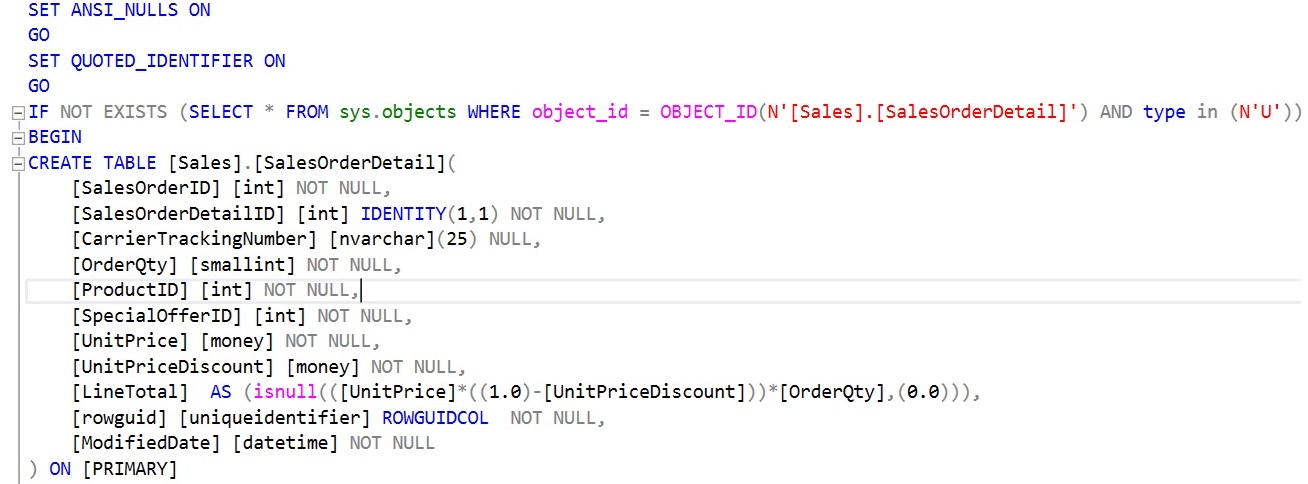
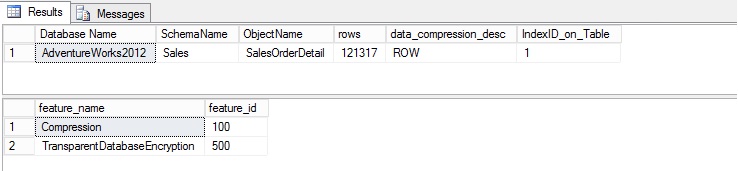
In this blog post we will see what is Azure SQL Database,
how you can create one and play around with it. Microsoft documentation says, ‘Azure
SQL Database is a relational database-as-a service using the Microsoft SQL
Server Engine. SQL Database is a high-performance, reliable, and secure
database you can use to build data-driven applications and websites in the
programming language of your choice, without needing to manage infrastructure.’
As said above, you need not worry about managing your infrastructure, like patching the OS, managing windows security, Memory and CPU usage, etc. Only thing which you get and can work on with is SQL database which will reside on Cloud. It’s Just the database
Now let’s see how to create an Azure SQL Database. Firstly, you need to have an Azure subscription. You can go to
Microsoft Azure page and get free 30 days trail to play with.
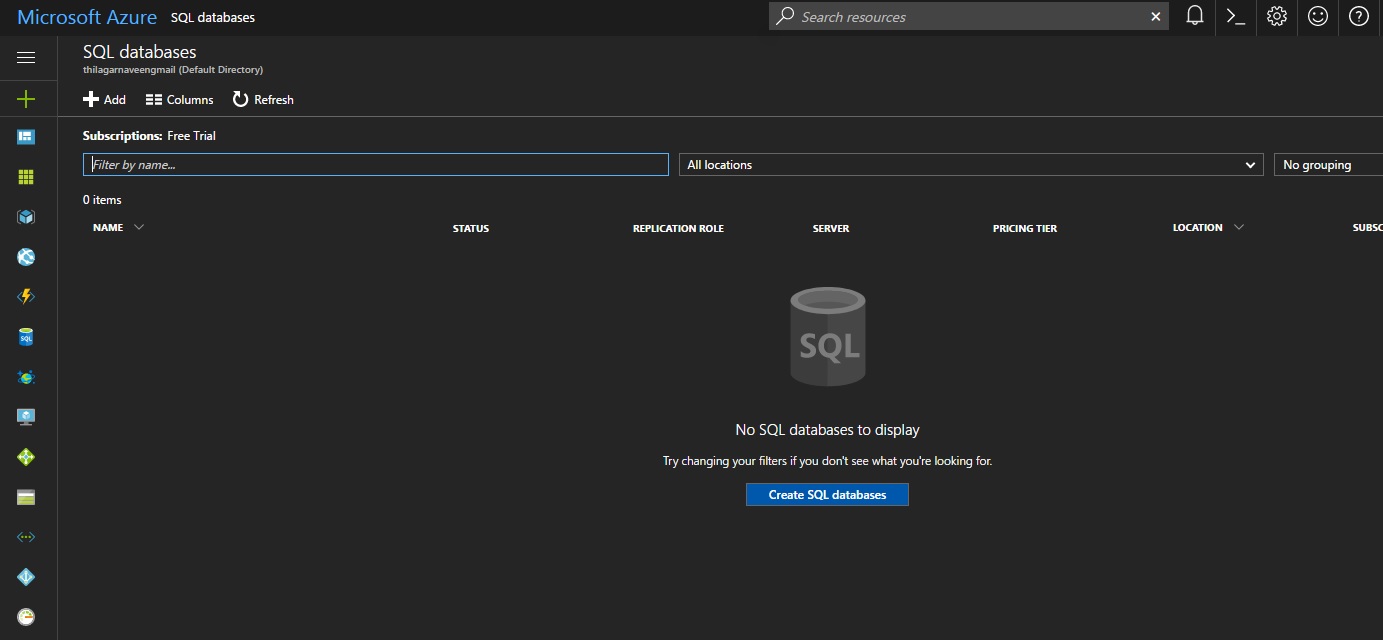
This is how the new home page looks like 😊 This portal has lots of stuffs.
To create an Azure SQL database, click on SQL Databases on the left which will take you to this page.
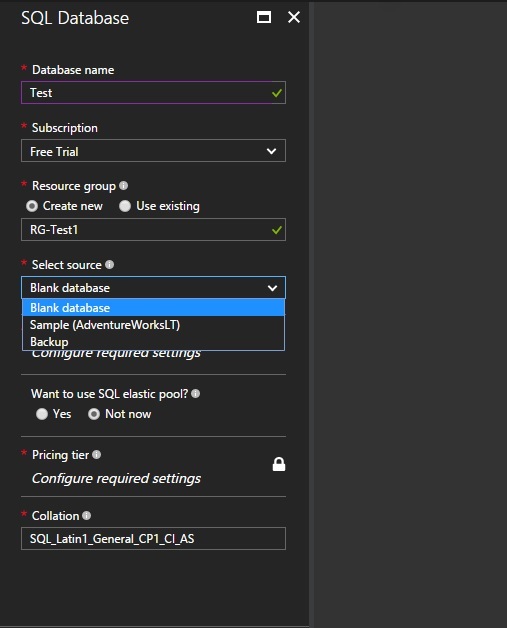
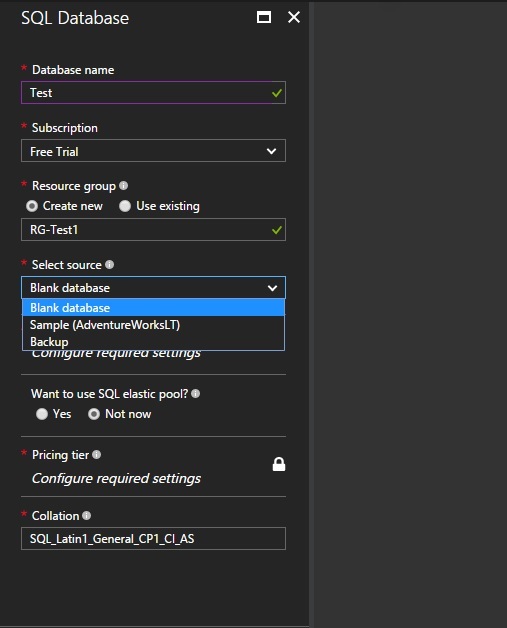
Now we have to provide some set of parameters to initiate the deployment.
Database Name- Would be your Azure SQL database name
Subscription- You need to choose which subscription you are going to use to this database.
Resource Group - A resource group is a container that holds related resources for an Azure solution. The resource group can include all the resources for the solution, or only those resources that you want to manage as a group. You can either create new one or use an existing resource group. You can also create the resource group separately.
Select Source – Provide the source for your database, if any. You get 3 options. Blank database, Sample AdventureWorks and backup.
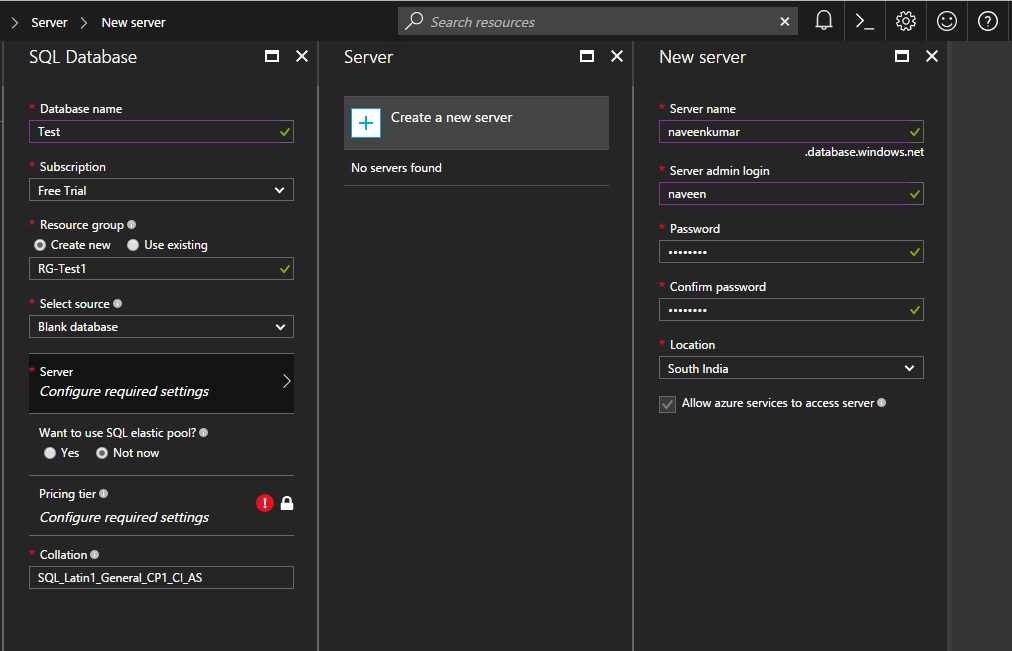
Next is server configuration
Server Name- Will be your SQL Server name on which the database is going to hosted
Server admin login – SQL login which will be created using which you can access the database
Password - Self explained
Location- This will decide on which data centre your data will reside. It’s always good to choose the one which will be closer to the users. So that you get better latency. Click
here to get all Azure Regions
Next is the pricing tire where you have to decide DTU (Database Transaction Units). This is something very important because you are dealing with resources and money 😊
DTUs are most useful for understanding the relative amount of resources between Azure SQL Databases at different performance levels and service tiers. Microsoft guarantees a certain level of resources for that database (independent of any other database in the Azure cloud) and providing a predictable level of performance. This amount of resources is calculated as a number of Database Transaction Units or DTUs, and is a blended measure of CPU, memory, I/O (data and transaction log I/O). You can use
Azure SQL Database DTU Calculator to determine the number of DTUs for your existing SQL Server database(s) as well as a recommendation of the minimum performance level and service tier that you need before you migrate to Azure SQL Database.
You need to measure below listed counters to determine the required DTU.
Processor - % Processor Time
Logical Disk - Disk Reads/sec
Logical Disk - Disk Writes/sec
Database - Log Bytes Flushed/sec
You get 4 service tires from which you have to choose
Basic - Best suited for a small database, supporting typically one single active operation at a given time. Examples include databases used for development or testing, or small-scale infrequently used applications.
Standard - The go-to option for cloud applications with low to medium IO performance requirements, supporting multiple concurrent queries. Examples include workgroup or web applications.
Premium - Designed for high transactional volume with high IO performance requirements, supporting many concurrent users. Examples are databases supporting mission critical applications.
Premium RS - Designed for IO-intensive workloads that do not require the highest availability guarantees. Examples include testing high-performance workloads, or an analytical workload where the database is not the system of record.
Click
here to know more information about each tire. For this demo, I will be using Basic tire which is sufficient.
Then set your database collation and you are all set to create your database. Now we have successfully created a new Azure SQL database.
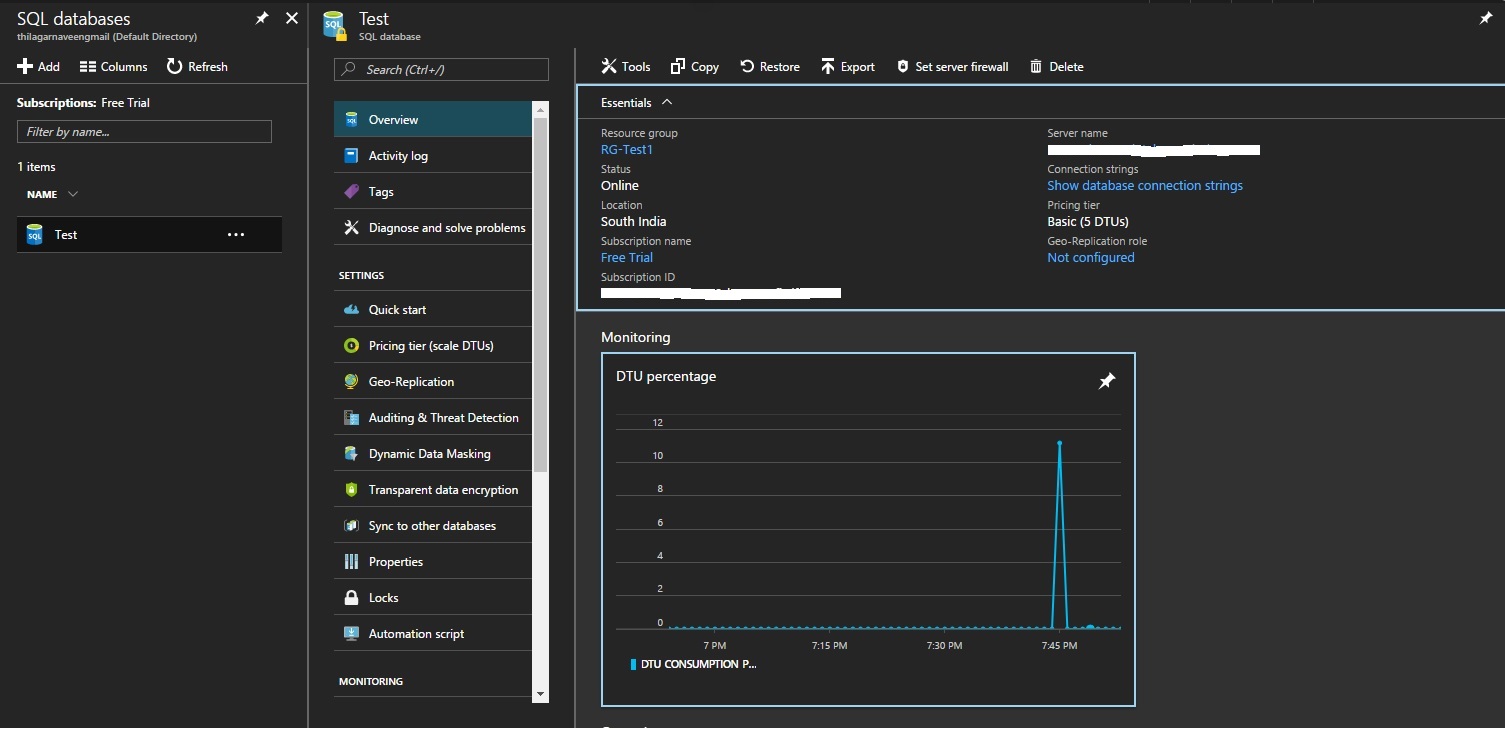
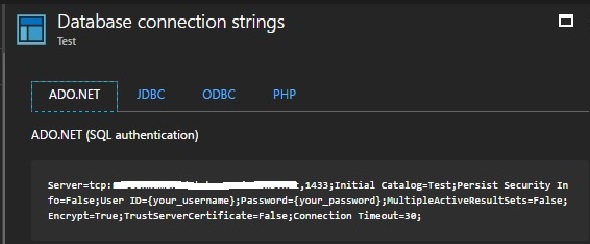
Now let’s look at the connection string, so that we can connect to our Azure SQL database from Management Studio. In the above pic, on the right side we have ‘Show database connection strings’. Once you click that, you will get different types of connection strings. We already have user name and password, in the ADO.NET string, we can get the server name.
Now I will open my management studio on my local machine and will pass on all the details. We get a nice little screen which says, client IP address does not have access to the server.
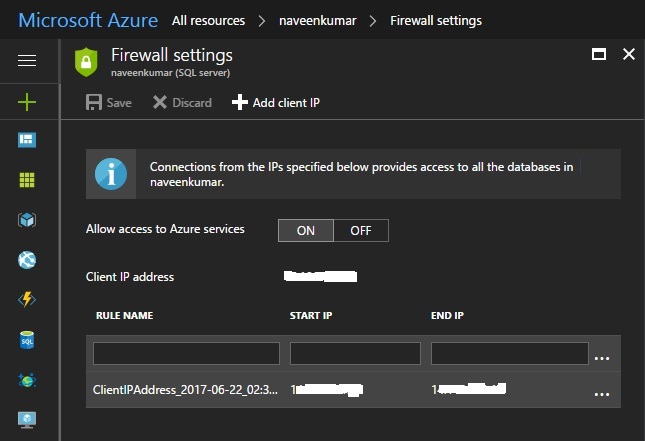
Coolest thing about this window is, you just have to sign in with your Azure credentials and at the back it’s going to create a firewall rule which will allow connections from that particular machine. So now when I go back to the firewall settings in Azure portal, I can see we have a new firewall rule.
This is making our life really easy. You can still come here and create your own rules. Now I should be able to connect to my Azure SQL database without any issues.
Now it’s like your normal on premise database. You can just create your tables and load data. For Azure SQL database, query store will be enabled by default to keep track of everything. We get it with 10 MB if max size, so it should be ok. I guess this initial size depends on what type of service tire we choose, but I am not completely sure about this.
You can also use Tools in Azure Portal to run T-SQL commands. As of now we have Query editor which is in preview but works fine and visual studio.
Once you click query editor, you have to authenticate again by passing on your login credentials.
Hope this gives you a basic idea about Azure SQL database. On my next post on Azure, we will see about migrating on premise database to Azure SQL database.
Cheers,
Naveen